Meta Unveils New Large-Language Model Operating on Intel and Qualcomm Platforms
Meta has just launched Llama 3, its latest large language model (LLM), designed to enhance the accuracy and safety of generative AI applications. In addition to this LLM, Meta has also introduced several new trust and safety tools, including Llama Guard 2, Code Shield, and CyberSec Eval 2, aimed at meeting industry standards and ensuring user safety. Although the development of the Llama 3 AI models is ongoing, Meta is making the initial two models available to the public immediately.
Users can experiment with Meta's first two LLMs now. Image used courtesy of Meta
The open-source Llama 3 integrates inherent safety features within the model and supports various hardware platforms. Meta has announced that Llama 3 will soon be compatible with all primary platforms, including cloud services and model API providers. Soon, companies such as AWS, Databricks, Google Cloud, Hugging Face, Kaggle, IBM WatsonX, Microsoft Azure, Nvidia NIM, and Snowflake will start hosting the Llama 3 LLM. Additionally, the LLM will be compatible with hardware from prominent manufacturers like AMD, AWS, Dell, Intel, Nvidia, and Qualcomm.
Intel and Qualcomm Swiftly Implement Llama 3 Across Hardware Platforms
Generative AI processors are required to swiftly manage significant data volumes and perform complex mathematical operations in parallel. This necessity applies to all processor types, whether graphics processing units (GPUs), neural processing units (NPUs), or tensor processing units (TPUs), often in combination with robust central processing units (CPUs). These processors, whether as standalone powerful coprocessors or as cores within system-on-chip (SoC) configurations, are crucial.
Using an SoC design, Qualcomm has integrated Llama 3 into its mobile processing architecture. Qualcomm collaborated closely with Meta in the development phase of Llama 3 to ensure compatibility with its top-line Snapdragon products, which boast integrated AI-capable NPU, CPU, and GPU cores.

Intel validated its AI product portfolio for the first Llama 3 8B and 70B models. Image used courtesy of Intel
Intel also played a pivotal role with Meta in tailoring Llama 3 for data center-scale processors. Intel previously adapted its Gaudi 2 AI accelerators for Llama 2, the preceding version of the LLM, and has now confirmed their compatibility with Llama 3. Furthermore, Intel’s Xeon, Core Ultra, and Arc processors have been tested and verified to work with Llama 3.
How Does Llama 3 and Other LLMs Function?
AI large language models (LLMs) like Llama 3 interpret datasets and transform them into formats that machines can understand. This capability enables generative AI to replicate human-like reasoning based on existing knowledge. The process involves the tokenization of words, akin to how a software compiler interprets keywords and converts them into CPU operation codes. Aspects such as grammar, syntax, and punctuation are also tokenized, forming a set of rules that guide AI in interpreting data and generating responses.
The greater the number of tokenized parameters, the more precise and lifelike the resulting output. Nonetheless, this precision must be carefully balanced against the computational burden required to tokenize, apply rules, and perform interpretation. Llama 3 is available in two models: one with eight billion parameters designed for higher-end edge AI use cases like smartphone processors, and another with 70 billion parameters intended for more robust data center environments.
Llama 3 utilizes a vocabulary of 128-K tokens for efficient data encoding and employs grouped query attention (GQA) in both its 8B and 70B models. These models are trained using sequences up to 8,192 tokens in length. To maintain data integrity, Meta implemented a masking technique that prevents self-attention across document boundaries.
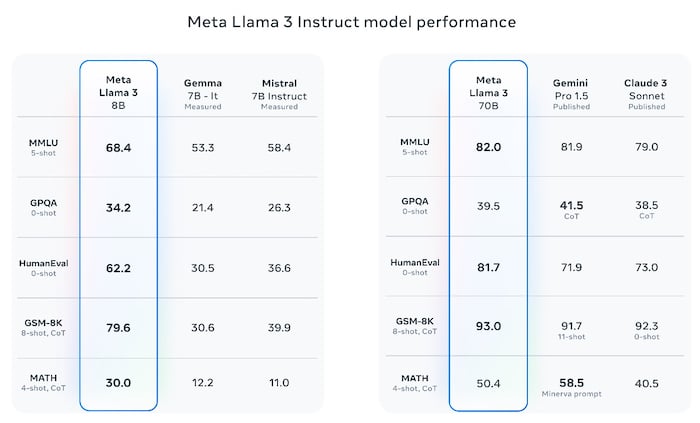
Llama 3 8B and 70B performance measures. Image used courtesy of Meta
In zero-shot learning scenarios, the AI model encounters data in questions it has not been explicitly trained on. For instance, it may be tasked to recognize a duck without having been previously exposed to duck images in its training set. The model must rely on its understanding of semantic relationships to deduce an answer.
Conversely, in n-shot learning scenarios (where n > 0), the AI model has exposure to at least n instances of the data related to the query in its training phase. Chain of thought (CoT) testing evaluates the model's logical reasoning capabilities in handling complex tasks, such as mathematical problems and physics calculations. Meta has benchmarked Llama using a specially curated human evaluation set comprising 1,800 prompts across 12 prevalent application scenarios.
Meta Prioritizes AI Safety
After more than a year of extensive AI utilization by the general public, concerns regarding safety, precision, and dependability have become increasingly important. In response, Meta has incorporated safety considerations by enabling developers to specifically enhance the models’ safety measures for various applications.
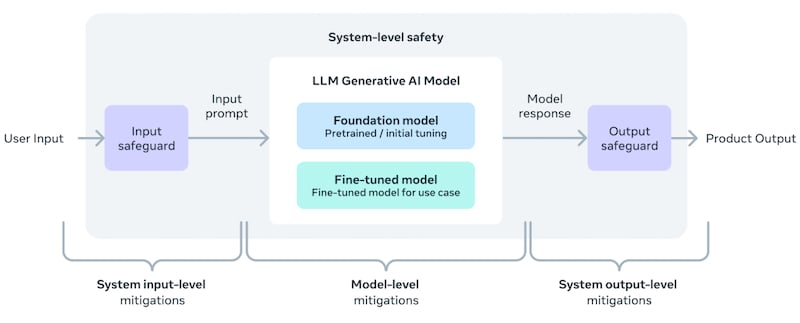
Llama 3 system-level safety model. Image used courtesy of Meta
Meta ensures a clear delineation between the developers and the testing scenarios of its models to avoid inadvertent overfitting. Overfitting in large language models (LLMs) occurs when a model, due to its complexity, virtually memorizes training data rather than learning to discern underlying patterns. Such overfitted models perform well with familiar training data but struggle significantly with new or varied information. A severely overfitted LLM can replicate data effectively but lacks independent thinking capabilities.
The Future Directions for Llama 3
The field of AI is continually evolving, and the Meta Llama 3 LLM is continuously being refined as part of this ongoing development process.
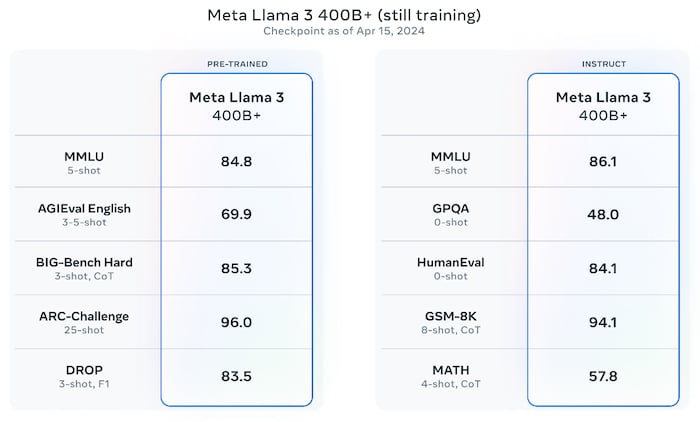
Preview of future Llama 3 performance. Image used courtesy of Meta
While Meta has released the 8B and 70B models, it continues to develop a larger 400B parameter version. This 400 billion parameter model exhibits enhanced accuracy due to its expanded parameter set, yet its comparison with the 8B and 70B models on performance charts indicates diminishing returns on some benchmarks. Consequently, it can be deduced that the demand for increasingly sophisticated AI hardware will persist unabated.
Images used courtesy of Meta.






